Realtime caching with automatic invalidation
Caches are seperate local copies of data, maintained close to application code. They speed up data access, reducing latency and increasing scalability.
The challenge with caching is invalidation, i.e.: keeping the cache up-to-date. This is famously one of the hardest problems in computer science.
Electric solves cache invalidation for you by automatically keeping data in sync.
The problem with stale data
A lot of systems today use ad-hoc mechanisms to maintain caches and keep them up-to-date. This leads to engineering complexity, stale data and bad user experience.
This applies both to the data plumbing and the algorithms used to expire data.
Data plumbing
Say you're maintaining a cache of recently updated projects. What happens when one of those projects is renamed? You need to update the cache. So you need a mechanism for reliably propagating updates from your main data source to the cache.
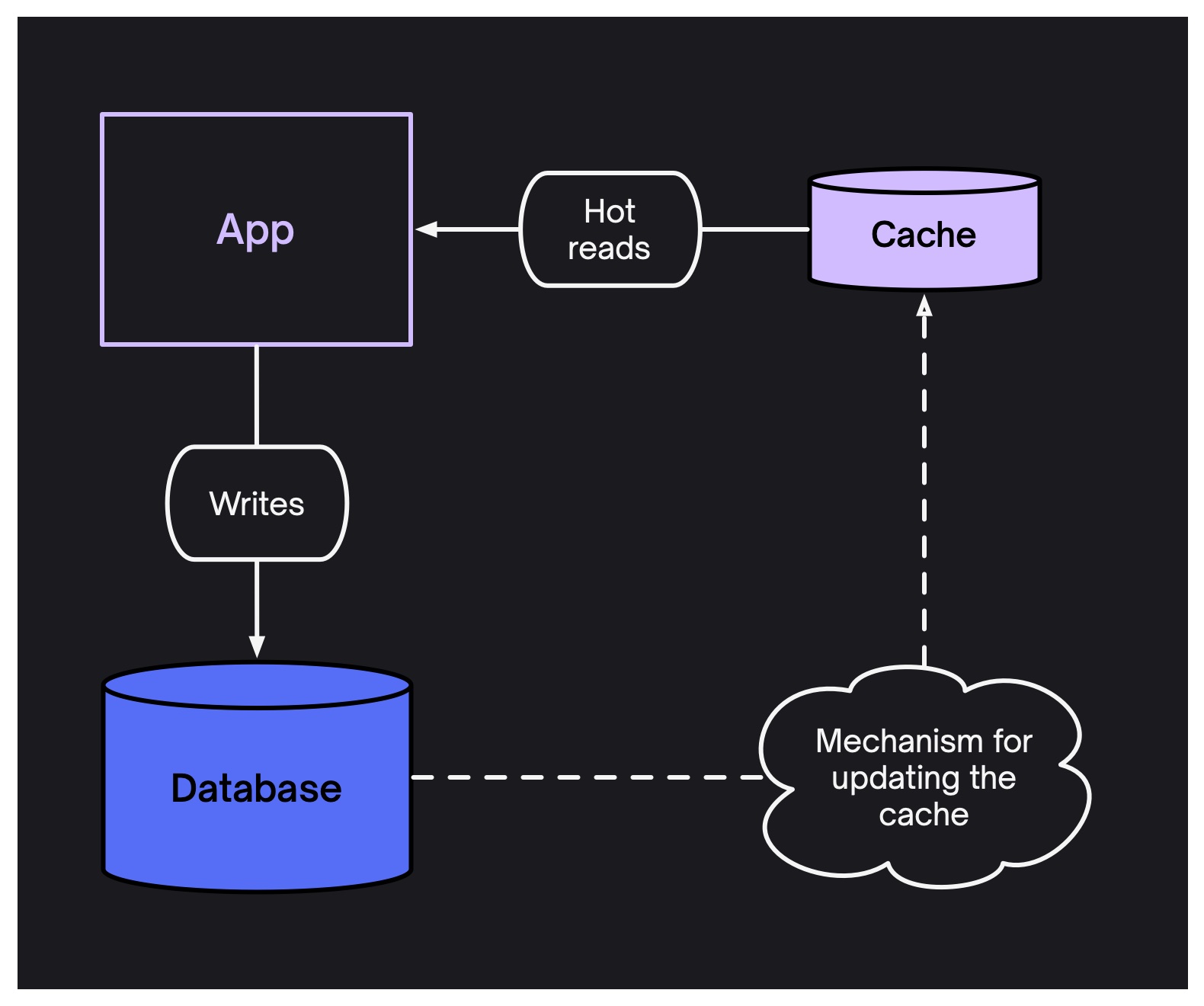
This means you need durability, at-least-once delivery and to be able to recover from downtime. It's easy to get sucked into engineering complexity and it's easy to make mistakes, so a cache either gets stuck with stale data or wiped too often.
Stale data
It's hard to know when a cache entry should be invalidated. Often, systems use ad-hoc expiry dates and "time to live" (or "ttls").
This leads to stale data, which can lead to confused users, integrity violations and having to write code to put safeguards around data you can't trust.
Solved by Electric
Electric solves data plumbing with realtime sync and solves stale data with automated cache invalidation.
Realtime sync
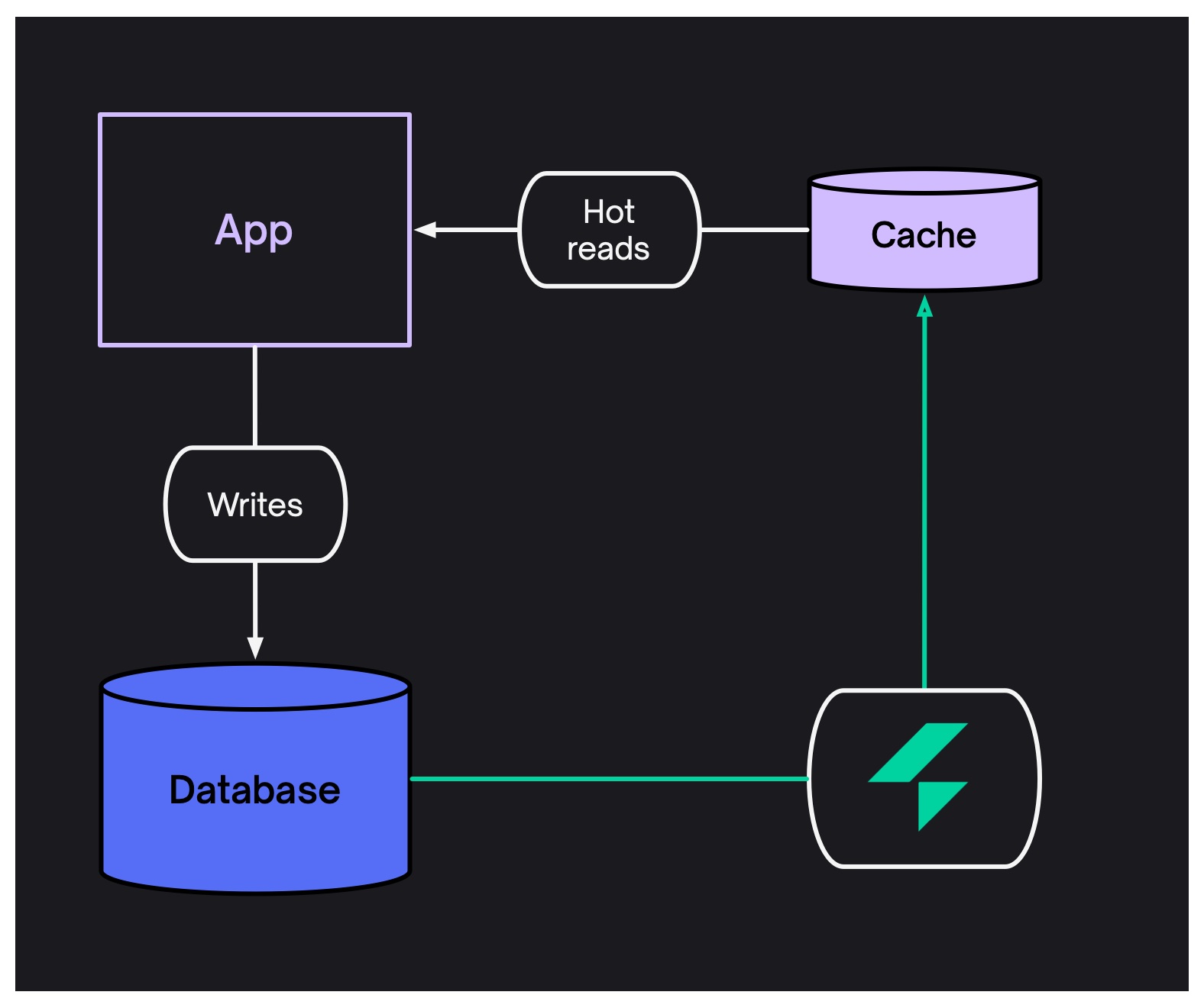
Electric syncs data into caches in realtime. It's fast and reliable, handles durability/delivery and reconnecting after downtime. You just declare the Shape of the data you want in the cache and Electric keeps it in sync.
Automated cache invalidation
Electric automatically manages the data in your local cache for you. When the data changes, the changes are synced to the local cache which is automatically updated.
You don't need to manage cache invalidation seperately or set expiry dates of TTLs on the records in the cache. Electric handles it for you.
Real world example
Let's look at a real world example, syncing data into a Redis cache. You can see the full source code here.
Maintaining a Redis cache
Many applications use Redis as a local cache. With Electric, you can define a Shape and sync it into a Redis hash. The shape comes through as a log of insert, update and delete messages. Apply these to the Redis hash and the cache automatically stays up-to-date:
import { createClient } from 'redis'
import { ShapeStream, Message, isChangeMessage } from '@electric-sql/client'
// Create a Redis client
const REDIS_HOST = `localhost`
const REDIS_PORT = 6379
const client = createClient({
url: `redis://${REDIS_HOST}:${REDIS_PORT}`,
})
client.connect().then(async () => {
console.log(`Connected to Redis server`)
// Clear out old data on the hash.
client.del(`items`)
// Lua script for updating hash field. We need to merge in partial updates
// from the shape log.
const script = `
local current = redis.call('HGET', KEYS[1], KEYS[2])
local parsed = {}
if current then
parsed = cjson.decode(current)
end
for k, v in pairs(cjson.decode(ARGV[1])) do
parsed[k] = v
end
local updated = cjson.encode(parsed)
return redis.call('HSET', KEYS[1], KEYS[2], updated)
`
// Load the script into Redis and get its SHA1 digest
const updateKeyScriptSha1 = await client.SCRIPT_LOAD(script)
const itemsStream = new ShapeStream({
url: `http://localhost:3000/v1/shape/items`,
})
itemsStream.subscribe(async (messages: Message[]) => {
// Begin a Redis transaction
//
// FIXME The Redis docs suggest only sending 10k commands at a time
// to avoid excess memory usage buffering commands.
const pipeline = client.multi()
// Loop through each message and make writes to the Redis hash for action messages
messages.forEach((message) => {
if (!isChangeMessage(message)) return
console.log(`message`, message)
// Upsert/delete
switch (message.headers.operation) {
case `delete`:
pipeline.hDel(`items`, message.key)
break
case `insert`:
pipeline.hSet(
`items`,
String(message.key),
JSON.stringify(message.value)
)
break
case `update`: {
pipeline.evalSha(updateKeyScriptSha1, {
keys: [`items`, String(message.key)],
arguments: [JSON.stringify(message.value)],
})
break
}
}
})
// Execute all commands as a single transaction
try {
await pipeline.exec()
console.log(`Redis hash updated successfully with latest shape updates`)
} catch (error) {
console.error(`Error while updating hash:`, error)
}
})
})Next steps
Get started with Electric to simplify your stack and avoid stale data.